中文
中文 















'%3e%3cg%20id='全部文章'%20transform='translate(296.000000,%20180.000000)'%3e%3cg%20id='logo-反白标识'%20transform='translate(24.000000,%20130.000000)'%3e%3ccircle%20id='椭圆形'%20fill='%230652FB'%20cx='12'%20cy='12'%20r='12'%3e%3c/circle%3e%3cg%20id='图标'%20transform='translate(4.481119,%204.363636)'%20fill='%23FFFFFF'%3e%3crect%20id='矩形'%20x='12.0775728'%20y='0'%20width='2.96018942'%20height='2.95983087'%3e%3c/rect%3e%3cpath%20d='M9.47260613,2.84143763%20L9.472,5.81143763%20L12.4327956,5.81184712%20L12.4327956,12.323475%20L9.472,12.3234376%20L9.47260613,15.2727273%20L2.96018942,15.2727273%20L2.96,12.3234376%20L3.50830476e-14,12.323475%20L3.64153152e-14,5.81184712%20L2.96,5.81143763%20L2.96018942,2.84143763%20L9.47260613,2.84143763%20Z%20M3.078,12.1944376%20L9.354,12.1944376%20L9.354,5.91943763%20L3.078,5.91943763%20L3.078,12.1944376%20Z'%20id='形状结合'%3e%3c/path%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
'%20fill='%23818F9F'%20fill-rule='nonzero'%3e%3cg%20id='新闻资讯'%20transform='translate(0.000000,%207141.000000)'%3e%3cg%20id='新闻列表'%20transform='translate(1310.000000,%20278.000000)'%3e%3cg%20id='编组-18备份-3'%20transform='translate(0.000000,%20261.000000)'%3e%3cg%20id='编组-23'%20transform='translate(24.000000,%2048.000000)'%3e%3cg%20id='icon/时间'%20transform='translate(0.000000,%201.000000)'%3e%3cg%20id='编组-2'%20transform='translate(0.583333,%200.583333)'%3e%3cpath%20d='M6.41666667,0%20C9.96049381,0%2012.8333333,2.87283952%2012.8333333,6.41666667%20C12.8333333,9.96049381%209.96049381,12.8333333%206.41666667,12.8333333%20C2.87283952,12.8333333%200,9.96049381%200,6.41666667%20C0,2.87283952%202.87283952,0%206.41666667,0%20Z%20M6.41666667,0.875%20C3.35608868,0.875%200.875,3.35608868%200.875,6.41666667%20C0.875,9.47724466%203.35608868,11.9583333%206.41666667,11.9583333%20C9.47724466,11.9583333%2011.9583333,9.47724466%2011.9583333,6.41666667%20C11.9583333,3.35608868%209.47724466,0.875%206.41666667,0.875%20Z'%20id='椭圆形'%3e%3c/path%3e%3cpath%20d='M6.125,3.06414484%20C6.3464892,3.06414484%206.52953639,3.22873461%206.55850614,3.44227868%20L6.5625,3.50164484%20L6.5625,6.63133333%20L9.0771479,8.11945819%20C9.26776239,8.23225705%209.34147212,8.46712497%209.25765099,8.66565542%20L9.23085444,8.71878014%20C9.11805558,8.90939463%208.88318766,8.98310436%208.68465721,8.89928323%20L8.63153249,8.87248668%20L5.90219229,7.25736044%20C5.788131,7.18986304%205.71187024,7.07505532%205.69240923,6.94625699%20L5.6875,6.8808462%20L5.6875,3.50164484%20C5.6875,3.26002026%205.88337542,3.06414484%206.125,3.06414484%20Z'%20id='路径-3'%3e%3c/path%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
'%20fill='%23818F9F'%20fill-rule='nonzero'%3e%3cg%20id='全部文章'%20transform='translate(296.000000,%201508.000000)'%3e%3cg%20id='内容1备份-2'%20transform='translate(0.000000,%20485.000000)'%3e%3cg%20id='编组-4'%20transform='translate(24.000000,%2024.000000)'%3e%3cg%20id='浏览量'%20transform='translate(390.000000,%20140.000000)'%3e%3cg%20id='icon/浏览量'%20transform='translate(0.000000,%201.000000)'%3e%3cg%20id='liulanliang'%20transform='translate(0.500000,%202.166667)'%3e%3cpath%20d='M7.5,0%20C11.484375,0%2015,3.33731156%2015,5.83333333%20C15,8.32935511%2011.484375,11.6666667%207.5,11.6666667%20C3.515625,11.6666667%200,8.32935511%200,5.83333333%20C0,3.33731156%203.515625,0%207.5,0%20Z%20M7.5,1%20C5.84272981,1%204.28195238,1.6656135%203.09467893,2.58904841%20C1.88385786,3.53079813%201,4.75266462%201,5.83333333%20C1,6.91400205%201.88385786,8.13586854%203.09467893,9.07761826%20C4.28195238,10.0010532%205.84272981,10.6666667%207.5,10.6666667%20C9.15727019,10.6666667%2010.7180476,10.0010532%2011.9053211,9.07761826%20C13.1161421,8.13586854%2014,6.91400205%2014,5.83333333%20C14,4.75266462%2013.1161421,3.53079813%2011.9053211,2.58904841%20C10.7180476,1.6656135%209.15727019,1%207.5,1%20Z%20M7.5,3.16666667%20C8.97275933,3.16666667%2010.1666667,4.360574%2010.1666667,5.83333333%20C10.1666667,7.30609267%208.97275933,8.5%207.5,8.5%20C6.02724067,8.5%204.83333333,7.30609267%204.83333333,5.83333333%20C4.83333333,4.360574%206.02724067,3.16666667%207.5,3.16666667%20Z%20M7.5,4.16666667%20C6.57952542,4.16666667%205.83333333,4.91285875%205.83333333,5.83333333%20C5.83333333,6.75380792%206.57952542,7.5%207.5,7.5%20C8.42047458,7.5%209.16666667,6.75380792%209.16666667,5.83333333%20C9.16666667,4.91285875%208.42047458,4.16666667%207.5,4.16666667%20Z'%20id='形状结合'%3e%3c/path%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e)

在网络数据采集工作中,你是否遇到过这样的困境:精心编写的Python爬虫,在运行几分钟后就被目标网站无情屏蔽,随之而来的是403禁止访问或验证码挑战?事实上,这往往不是你的代码有误,而是你的网络身份——IP地址——暴露了机器的身份。面对现代网站日益严格的反爬虫机制,一个高效、稳定的海外代理IP池已成为专业爬虫项目的标配。

为什么Python爬虫必须使用代理IP?
简单来说,任何网站都有安全机制。当它发现同一个IP地址在短时间内发起大量、高频的请求时,会立刻将其识别为爬虫机器而非正常用户,从而进行封禁。这就像一家商店发现同一个人每隔几秒就进店一次,自然会起疑。
直接使用本地网络进行大规模爬取,无异于“裸奔”,不仅效率低下,更会导致你的真实IP被永久拉黑。因此,为爬虫配置代理IP的核心目的,是“隐匿身份、分散请求、模拟真人”,让每一次请求都像是来自世界不同角落的真实用户,从而安全、持续地获取数据。
实战指南:为Python爬虫配置OnesProxy代理IP
为你的Python爬虫项目接入OnesProxy的代理服务,通常只需三个清晰的步骤。下面以最常用的`requests`库为例进行说明。
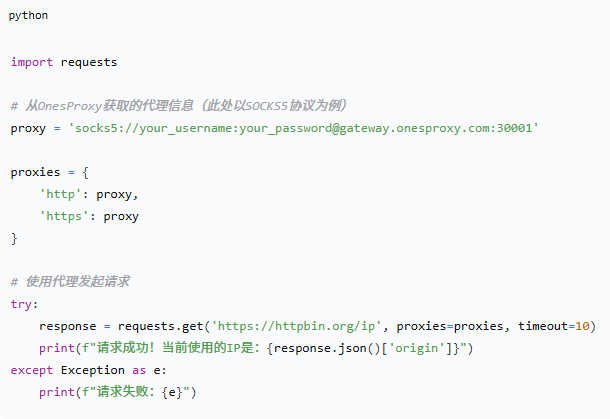
第一步:获取OnesProxy代理信息
首先,你需要在OnesProxy后台获取可用的代理服务器信息。以动态住宅IP(非常适合高频轮换的爬虫场景)为例,你将获得一个代理链接或一组包含主机、端口、用户名和密码的信息。格式通常如下:
`socks5://username:password@gateway.onesproxy.com:port`
第二步:在Python代码中集成代理
拿到代理信息后,你只需在发起网络请求时,将其作为参数传递给请求库。OnesProxy支持主流的HTTP/HTTPS和SOCKS5协议,兼容性极佳。
基础配置示例:
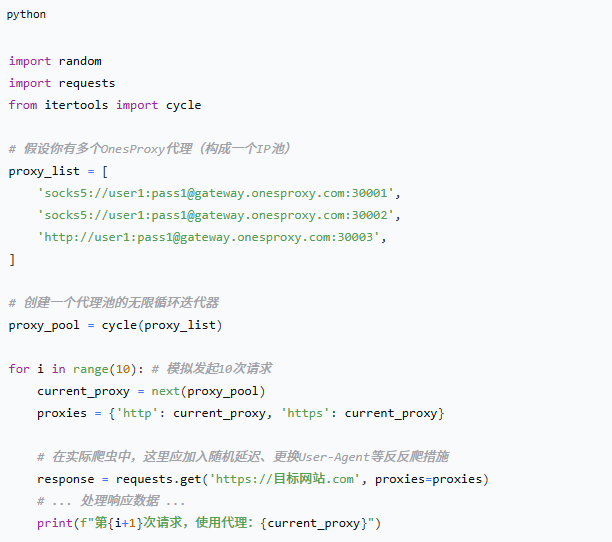
第三步:实现智能IP轮换与管理
对于大型爬虫项目,手动配置单个代理是不够的。你需要从OnesProxy获取一个庞大的IP代理池,并让爬虫自动、随机地切换使用它们,最大化地模拟分散的真人访问。
进阶池化方案:
最佳实践:让爬虫运行得更稳、更久
仅仅接入代理IP只是开始,遵循以下最佳实践,能让你的爬虫项目如虎添翼:
1.选择正确的IP类型:对于高频数据采集,强烈推荐使用OnesProxy的动态住宅IP池。它们来自真实的家庭网络,IP地址会自动轮换,隐蔽性远超数据中心IP,能有效规避大部分反爬系统的识别。
2.完善请求头管理:代理IP解决的是网络层身份问题。你还需要在代码中设置合理的`User-Agent`、`Referer`等请求头,让每一次请求在应用层也显得“正常”。
3.添加优雅的错误处理与重试:网络请求总有不确定性。在你的代码中加入超时设置、状态码检查,并针对连接失败、代理失效等异常设计重试机制(例如将失效代理移出当前池)。
4.遵守robots协议与法律:始终尊重目标网站的`robots.txt`文件,控制合理的请求速率,避免对目标网站服务器造成压力,在法律和道德框架内进行数据采集。
OnesProxy:为你的Python爬虫提供动力引擎
当你的爬虫业务从兴趣转向专业,OnesProxy能为你提供坚实的后盾:
海量高质量住宅IP:我们的IP资源来自全球真实家庭网络,纯净度高,访问成功率高,是应对严格反爬策略的利器。
稳定高速的连接:无论是静态IP用于需要会话保持的任务,还是动态IP池用于大规模并发采集,我们都能提供低延迟、高可用的连接保障。
易于集成的API:除了固定代理,OnesProxy还提供便捷的API接口,让你能动态获取、管理IP,实现与爬虫架构的无缝集成。
专业的技术支持:我们理解开发者的需求,提供清晰文档和技术支持,助你快速解决集成中的任何问题。

为你的Python爬虫配置专业的代理IP,绝不是一项可有可无的装饰,而是决定项目成败的核心技术决策。选择OnesProxy,就是为你的数据采集引擎注入了最可靠的“隐身”与“分身”能力。
立即访问OnesProxy官网,获取适合你爬虫项目的代理IP解决方案,无论是公开数据调研、价格监控还是市场分析,都能让你的爬虫在数据海洋中畅行无阻,高效完成任务!